Ramka danych CAN i mechanizmy zapewniające niezawodność

Współczesne systemy sterowania, automatyki przemysłowej, pojazdy elektryczne oraz aplikacje embedded w coraz większym stopniu opierają się na deterministycznej i niezawodnej komunikacji czasu rzeczywistego. Jednym z fundamentów takiej komunikacji pozostaje magistrala CAN / ramka danych CAN, której skuteczność wynika nie tylko z odporności na zakłócenia, ale również z przemyślanej struktury ramki danych, mechanizmu arbitrażu oraz zaawansowanych metod wykrywania błędów. Zrozumienie budowy ramki CAN oraz zasad jej transmisji jest kluczowe przy projektowaniu systemów wymagających gwarantowanego czasu reakcji i wysokiej integralności danych.
Ramka danych CAN. Formaty
Klasyczny protokół CAN obsługuje dwa formaty ramki danych CAN. Zasadniczo różnią się one tylko długością identyfikatora CAN. Classical Base Frame Format (CBFF)” obsługuje długość 11 bitów dla identyfikatora CAN, a „Classical Extended Frame Format (CEFF)” obsługuje długość 29 bitów dla identyfikatora CAN.
Format ramki podstawowej (CAN2.0A)
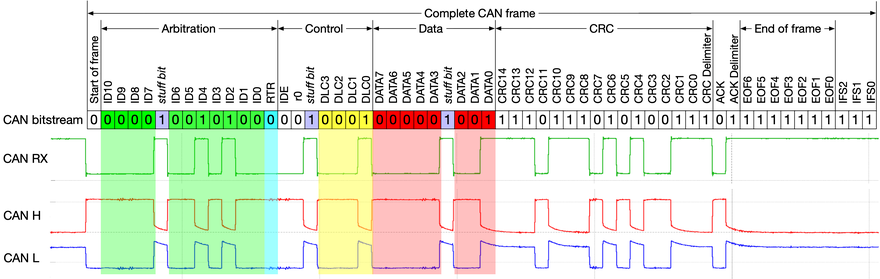
- Ramka danych CAN rozpoczyna się od bitu „Start Of Frame” (SOF). Za pomocą tego bitu wszystkie połączone węzły w sieci synchronizują się na czas trwania jednej transmisji ramki danych CAN
- „Pole arbitrażu”, dostarcza identyfikator ramki CAN
- „pole kontrolne” zawiera bit „Identifier Extension (IDE)” (dominujący “0”) umożliwia definicję formatu ramki podstawowej CAN (w odróżnieniu do formatu rozszerzonego), oraz „Data Length Code (DLC)” wskazują wielkość kolejnego „pola danych”
- „polu danych” znajdują się dane aplikacji, które mogą zawierać się w przedziale od zera do maksymalnie ośmiu bajtów danych
- „Cyclic Redundant Check (CRC)” pole zawierające sumę kontrolną
- „Acknowledge (ACK)” gdy ramkę danych przesłano poprawnie, aż do tego momentu, wszystkie węzły odbiorcze potwierdzają poprawność poprzez przesłanie dominującego bitu ACK.
- „End Of Frame (EOF)”, koniec ramki – 7 kolejnych bitów recesywnych;
Kolejne ramki oddziela pole przerwy które zawiera minimum 3 bity recesywne
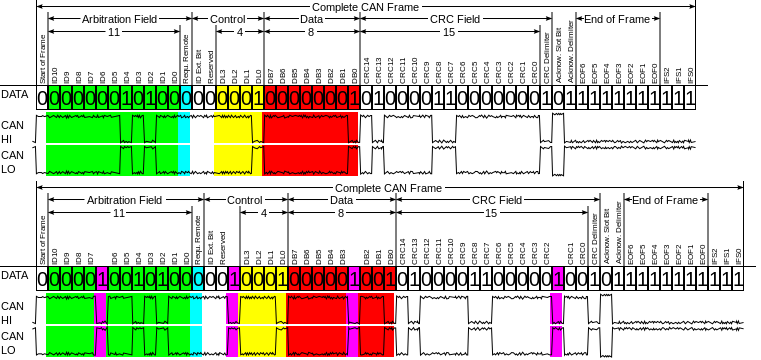
Format ramki rozszerzonej (CAN2.0B)
Ramka danych CAN – różnice. Podstawowa różnica między formatem ramki rozszerzonej a formatem ramki podstawowej polega na długości stosowanego identyfikatora CAN. 29-bitowy identyfikator składa się z 11-bitowego identyfikatora („identyfikator bazowy”) i 18-bitowego rozszerzenia („rozszerzenie identyfikatora”). Rozróżnienie pomiędzy formatem ramki podstawowej a formatem ramki rozszerzonej odbywa się za pomocą bitu IDE. W przypadku formatu ramki rozszerzonej (29-bitowy CAN ID) bit IDE jest przekazywany recesywnie; w przypadku formatu ramki podstawowej (11-bitowy CAN ID) dominująco. Format ramki rozszerzonej ma pewne kompromisy. Czas opóźnienia w sieci jest dłuższy, ramki danych w formacie rozszerzonym wymagają większej szerokości pasma (około 20%), a wydajność wykrywania błędów jest niższa (ponieważ wybrany wielomian dla 15-bitowego CRC optymalizuje się dla długości ramki do 112 bitów).
Od 2003 r. wszystkie implementacje klasycznej sieci CAN muszą być zdolne do obsługi obu formatów ramek sieci CAN. Starsze implementacje mogą albo akceptować tylko format ramki podstawowej, albo tolerować tylko format ramki rozszerzonej.
Transmisja w systemach czasu rzeczywistego i proces arbitrażu bitowego
W przetwarzaniu w czasie rzeczywistym pilność danych do wymiany w sieci może się znacznie różnić: szybko zmieniający się wymiar, np. obciążenie silnika, jest przesyłany częściej i dlatego z mniejszym opóźnieniem niż inne wymiary, np. temperatura silnika.
Priorytet, z jakim przesyłane są ramki danych w porównaniu z innymi, mniej pilnymi ramkami danych, jest określany przez przypisany identyfikator CAN. Priorytety przydziela się podczas projektowania systemu. Identyfikator CAN składa się z 11-bitowej lub 29-bitowej wartości binarnej. Najniższa wartość ma najwyższy priorytet; im wyższa wartość identyfikatora, tym niższy jest priorytet.
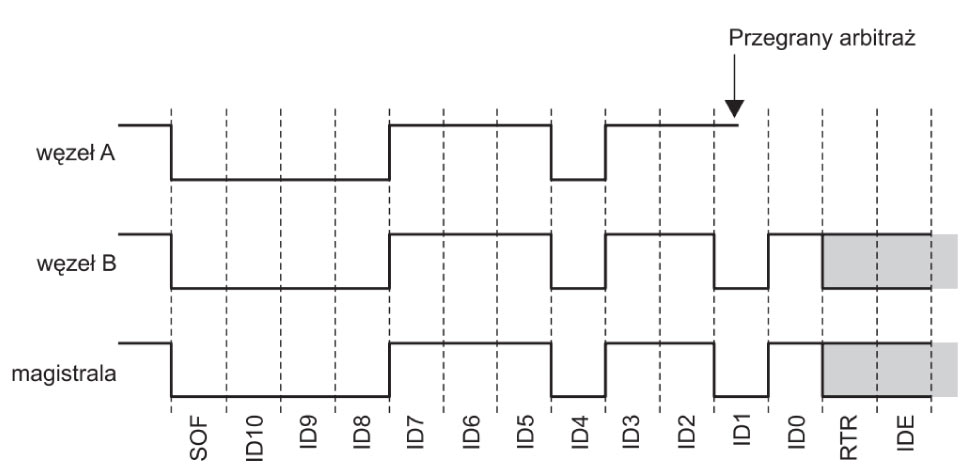
W przypadku, gdy o dostęp do sieci ubiega się jednocześnie nie jedna ramka danych CAN a kilka ramek, dostęp do sieci jest negocjowany poprzez bitowe porównanie identyfikatorów CAN konkurujących ramek. Mechanizm ten nazywa się arbitrażem bitowym.
Węzły nadają informację tak długo, dopóki zapis jej jest zgodny z sekwencją bitów obecnych w magistrali. Jeżeli wysłany zostanie bit recesywny, natomiast sygnał główny będzie miał w tym momencie wartość równą logicznemu zeru (bit dominujący), dany węzeł przerywa
nadawanie i przechodzi w stan odbioru informacji. Węzeł którego transmisję przerwano będzie próbował nadać swoją ramkę danych CAN po zakończeniu bieżącej transmisji i ponownym udostępnieniu sieci.
Taki przebieg arbitrażu powoduje, że nie traci się podczas transmisji żadnego bitu od priorytetowego węzła, a przy tym nie wydłuża się czas nadawania pojedynczego komunikatu.
W ten sposób żądania transmisji są obsługiwane w kolejności ich ważności dla systemu jako całości. Okazuje się to szczególnie korzystne w sytuacjach przeciążenia. Ponieważ dostęp do sieci jest priorytetowy na podstawie identyfikatora ramki danych CAN, możliwe jest zagwarantowanie niskich czasów opóźnień indywidualnych w systemach czasu rzeczywistego.
Wykrywanie i sygnalizacja błędów
Aby zapewnić wysoką niezawodność sieci, warstwa łącza danych CAN implementuje pięć mechanizmów wykrywania błędów w celu osiągnięcia najwyższej niezawodności:
• Kontrola sumy CRC: porównanie sumy kontrolnej na końcu transmisji w układzie odbiorczym z wartością początkową przesłaną z układu nadawczego. Jeśli nie są one zgodne, to wystąpił “błąd CRC”.
• Sprawdzanie formatu ramki: Mechanizm ten weryfikuje strukturę transmitowanej ramki poprzez sprawdzenie pól bitowych względem ustalonego formatu i rozmiaru ramki. Błędy wykryte przez kontrolę ramki oznacza się jako „błędy formatu”.
• brak potwierdzenia odbioru: Odbiorniki ramek CAN potwierdzają odebrane ramki. Jeśli nadajnik nie otrzyma potwierdzenia, następuje sygnalizacja “błąd ACK”.
• Kontrola bitów: Zdolność nadajnika do wykrywania błędów opiera się na monitorowaniu sygnałów sieciowych. Każdy węzeł, który nadaje, również obserwuje poziom sygnału i w ten sposób wykrywa różnice między bitem wysłanym a odebranym. Pozwala to na niezawodne wykrywanie błędów globalnych i błędów lokalnych dla nadajnika.
• synchronizacja danych (bit stuffing): kodowanie poszczególnych bitów bada się na poziomie bitów. W transmisji stosuje się kodowanie „non-return-to-zero (NRZ)”. Zbocza synchronizacji generuje się poprzez wypychanie bitów. Oznacza to, że po pięciu kolejnych bitach o tej samej wartości logicznej, nadajnik wstawia bit wypychający do strumienia bitów. Ten bit wypychający ma wartość komplementarną, którą usuwa się przez węzły odbiorcze.
„Error Frame”
W przypadku wykrycia przynajmniej jednego z wyżej wymienionych błędów przez przynajmniej jeden węzeł, trwająca transmisja przerywa się poprzez wysłanie „Error Frame” (ciąg sześciu kolejnych bitów recesywnych lub dominujących). Powoduje to globalizację lokalnie wykrytego błędu, zmusza wszystkie inne węzły do samodzielnego wykrywania błędów, a tym samym zapewnia spójność danych w całej sieci. Po wysłaniu ramki błędu, odbiorcy oczekują retransmisji przerwanej ramki danych. Nadajnik spróbuje ponowić proces transmisji. Aby uniknąć sytuacji, w której błędny węzeł trwale zakłóca komunikację CAN, system posiada także mechanizm (“system fault confinement”) wymuszający na wadliwych węzłach wyłącznie swojego interfejsu CAN (“CAN error states”; “bus-off state”).
Informacja o błędzie jest przesyłana najpóźniej pod koniec komunikatu, aby układ nadający mógł powtórzyć wysłanie ramki danych.
Bezpieczeństwo i narzędzia programistyczne
CAN jest protokołem niskiego poziomu i nie obsługuje żadnych funkcji bezpieczeństwa. W standardowych implementacjach CAN nie ma również szyfrowania, co sprawia, że sieci te są otwarte na przechwytywanie ramek typu man-in-the-middle. W większości implementacji oczekuje się, że aplikacje wdrożą własne mechanizmy bezpieczeństwa, np. w celu uwierzytelnienia przychodzących poleceń lub obecności określonych urządzeń w sieci.
Podczas opracowywania lub rozwiązywania problemów z magistralą CAN, badanie sygnałów sprzętowych może być bardzo ważne. Analizatory logiczne i analizatory magistrali są narzędziami, które zbierają, analizują, dekodują i przechowują sygnały, dzięki czemu ludzie mogą oglądać szybkie przebiegi
Podsumowanie
Dzięki swoim zaletom sieć CAN jest jedną z najbardziej uniwersalnych sieci komunikacyjnych. Mimo że w ostatnich latach inne standardy pojawiają się w przemyśle jednak CAN ze względu na swoją specyfikę jeszcze długo będzie w powszechnym użytku.
źródła:
https://www.can-cia.org/can-knowledge/
https://en.wikipedia.org/wiki/CAN_bus
https://e2e.ti.com/blogs_/b/industrial_strength/posts/can-we-start-at-the-very-beginning
Inne wpisy

congatec z certyfikacją IEC 62443-4-1. Dlaczego to ważne dla projektów embedded?
Do niedawna w wielu projektach embedded bezpieczeństwo traktowano jako jeden z końcowych etapów prac. Najpierw dobór procesora, pamięci, interfejsów i systemu operacyjnego, a dopiero później pytanie: jak to zabezpieczyć? Dziś takie podejście przestaje wystarczać. Urządzenia przemysłowe, medyczne, transportowe czy…

Izolowane transmitery i splittery sygnałów Acromag
W aplikacjach przemysłowych liczy się nie tylko dokładność pomiaru, ale także szybkość uruchomienia i łatwość konfiguracji. Rozwiązania Acromag odpowiadają na te potrzeby. Umożliwiają szybką konfigurację przez USB z wykorzystaniem oprogramowania Windows® lub aplikacji Agility dla systemu Android. Oferta obejmuje…

CoreEnergy, CoreVolt 2 – nagradzane technologie Apacer dla niezawodnych systemów przemysłowych
Rozwój systemów edge AI, infrastruktury danych oraz aplikacji przemysłowych powoduje, że pamięć przestaje być jedynie komponentem o określonych parametrach. Coraz częściej staje się elementem krytycznym dla stabilności, wydajności i długoterminowego działania całego systemu. W tym kontekście szczególnego znaczenia nabierają technologie…